Хранилища данных - статьи
Технология изнутри
 | |
|
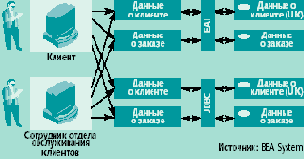
Рис. 1. Традиционно пользователь (например, сотрудник отдела обслуживания клиентов), желающий получить информацию из нескольких источников, может опрашивать источники лишь в порядке очереди, а это связано с более значительными затратами времени и средств, чем в случае одновременного доступа к множеству источников. В данном случае доступ пользователей к отдельным базам данных осуществляется с помощью программных средств интеграции приложений предприятия (enterprise application integration, EAI) и JDBC. |
Информационные системы традиционной архитектуры (рис. 1) в каждый момент обеспечивают доступ лишь к одному источнику данных. Объясняется это тем, что до недавнего времени не существовало ни универсального языка для данных, ни качественных метаданных. Если пользователи желают получить необходимые данные из нескольких источников, они должны располагать точными метаданными, описывающими хранимые данные в форматах, доступных для чтения на различных платформах. Между тем, программные и аппаратные средства не отличались ни достаточной мощностью, ни функциональностью, необходимой для осуществления доступа к распределенным данным.
Раньше разработчики вручную создавали адаптеры для работы с полученными из нескольких источников данными, используя при этом API соответствующих источников. Однако вручную созданные адаптеры не способны автоматически подстраиваться под обновляемые версии API.