Хранилища данных - статьи
Сравнение статистических данных ЕС и РФ
Имея два источника сведений о внешнеэкономической деятельности, можно попытаться сопоставить данные, одновременно анализируя всю совокупность ТНВЭД. Если сравнивать данные по группам товаров, то разница значений еще не может привести к каким-либо выводам, поскольку существуют естественные причины отклонения в данных ЕС и РФ:
В то же время не могут быть непосредственно использованы оригинальные переменные: вес нетто и стоимость, так как различные группы товаров характеризуются различной ценой и характерными объемами перемещаемых товаров. Кроме того, цель анализа — не выявление расхождений между данными ЕС и РФ, а определение величины риска, связанной с данной группой товаров, т. е. величины относительного несоответствия между данными. В связи с этим в качестве основных переменных выбраны относительные разности по стоимости и весу нетто, определяемые как:
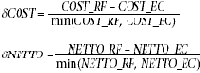
COST_RF, COST_ES — статистическая стоимость товаров данной группы по статистике РФ и EC соответственно, NETTO_RF, NETTO_ES — аналогичные показатели для веса нетто. Нормировка на минимальные значения обоснована, поскольку неизвестно истинное значение стоимости и веса, кроме того, это приближает распределение значений переменных к известному статистическому распределению (хотелось бы иметь распределение, хотя бы отдаленно напоминающее гауссово). Сравнить данные по всем группам можно, построив гистограмму для описанных переменных, показывающую, как часто встречается то или иное значение переменной (ось Х — значения переменной, Y — количество случаев, когда переменная принимала данное значение).
Oracle Darwin имеет утилиту для построения одно и двухмерных гистограмм данных, которой мы и воспользовались. На рис. 1 показаны нормированные распределения для относительного отклонения стоимости и веса для экспорта и импорта.
 |
Рис. 1. Распределение относительных отклонений стоимости и веса между данными ЕС и РФ |
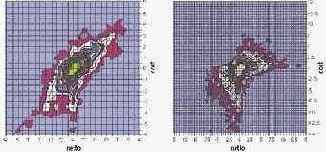 |
Рис. 2. Совместные распределения относительных отклонений стоимости веса. Слева — экспорт, справа — импорт |
Оказывается, этому есть простое объяснение.
Вес груза декларируется верно, но фальсифицируется наименование товара — в декларации указывается близкий по характеристикам товар с меньшей ставкой таможенной пошлины. В результате для определенных групп товаров наблюдается существенный прирост импорта по сравнению с данными ЕС. Эта схема ухода от таможенных платежей хорошо известна таможенным органам как «товар прикрытия».
Даже использование таких простейших способов анализа данных как гистограмма позволило выделить наличие определенных тенденций и оценить масштаб искажения данных. Более того, уже на этом этапе возможно сформулировать определенные критерии для отбора групп товаров наиболее подверженных фальсификациям. В то же время распределения, приведенные на рис. 1 и 2, показывают, что сделанный нами выбор переменных был не очень удачным с точки зрения алгоритмов кластеризации — плотность данных довольно монотонно падает от центра к краям распределения. Чтобы воспользоваться алгоритмами кластеризации нам пришлось переопределить переменные, введя следующие переменные:
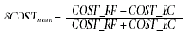
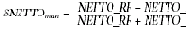
Основное отличие новых переменных — ограниченный диапазон принимаемых значений:
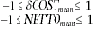
Распределение, аналогичное приведенному на рис. 2, в новых переменных показано на рис. 3.
 |
Рис. 3. Совместное распределение относительных отклонений по стоимости (dCOSTmean) и весу (dNETTOmean) для случаев импорта |
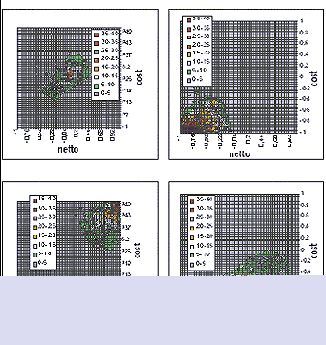 |
Рис. 4. Кластеры совместного распределения относительных отклонений по стоимости (dCOSTmean) и весу (dNETTOmean) для случаев импорта |
 |
Рис. 5. Найденный с помощью Darwin Match кластер в переменных netto-cost |